What is text summarization?
Text summarization is one of the Natural Language Processing (NLP) tasks where documents/texts are shortened automatically while holding the same semantic meaning. Summarization process generates short, fluent and accurate summary of the long documents. The main idea of text summarization is to find the subset of the most important information from the entire document and present it in a human readable format. Text summarization has its application in other NLP tasks such as Question Answering (QA), Text Classification, Text Generation and other fields.
Types of summarization
Based on how the texts are extracted from the documents, the summarization process can be divided into two types: extractive summarization and abstractive summarization.
- Extractive Summarization
Extractive summarization picks up the most important sentences directly from the documents and forms a coherent summary. This is done using a scoring function. Extractive summarization takes a sentence as an input and produces a probability vector as the output. This probability vector represents the probability of a sentence being included in the summary.
Implementing extractive summarization based on word frequency
We can implement extractive summarization using word frequency in five simple steps:
a. Creating word frequency table
We count the frequency of the words present in the text and create a frequency table which is a dictionary to store the count. While creating the frequency table, we do not account for the stop words present in the text and remove those words.
def frequency_table(text):
# all unique stopwords of english
stop_words = set(stopwords.words("english"))
words = word_tokenize(text)
freq_table = dict()
# creating frequency table to keep the count of each word
for word in words:
word = word.lower()
if word in stop_words:
continue
if word in freq_table:
freq_table[word] += 1
else:
freq_table[word] = 1
return freq_tableb. Tokenizing the sentences
Here we tokenize the sentences using NLTK’s sent_tokenize() method. This separates paragraphs into individual sentences.
def tokenize_sentence(text):
return sent_tokenize(text)c. Scoring the sentences using term frequency
Here, we score a sentence by its words, by adding frequency of every word present in the sentence excluding stop words. One downside of this approach is, if the sentence is long, the value of frequency increases.
def term_frequency_score(sentence, freq_table):
# dictionary to keep the score
sentence_value = dict()
for sentence in sentences:
for word, freq in freq_table.items():
if word in sentence.lower():
if sentence in sentence_value:
sentence_value[sentence] += freq
else:
sentence_value[sentence] = freq
return sentence_valued. Finding the threshold score
After calculating the term frequency, we calculate the threshold score.
def calculate_average_score(sentence_value):
# To compare the sentences within the text, we assign a score.
sum_values = 0
for sentence in sentence_value:
sum_values += sentence_value[sentence]
# Calculating average score of the sentence. This average score can be a good threshold.
average = int(sum_values / len(sentence_value))
return averagee. Generating the summary based on the threshold value
Based on the threshold value, we generate the summary of the text.
def create_summary(sentences, sentence_value, threshold):
# Applying the threshold value and storing sentences in an order into the summary.
summary = ''
for sentence in sentences:
if (sentence in sentence_value) and (sentence_value[sentence] > (1.2 * threshold)):
summary += " "+ sentence
return summary
- Abstractive Summarization
In abstractive summarization, the model forms its own phrases and sentences to provide a consistent summary. Abstractive summarization does not simply copy the sentences to form the summary but create new phrases that are relevant to the original document. This summarization technique uses deep learning techniques (like seq2seq) to paraphrase and shorten the original document.
Abstractive Summarization using Transformers
Transformers is an architecture which uses attention mechanisms to solve sequence to sequence problems while solving long term dependencies. Ever since it was introduced in 2017, transformers have been widely used in various NLP tasks such as text generation, question answering, text classification, language translation and so on. The transformer architecture consists of encoder and decoder parts. The encoder component consists of 6 encoders each of which consists of two sub layers: self-attention and feed forward networks. The input text is first converted into vectors using text embedding methods. Then the vector is passed into the self attention layer and the output from the self attention layer is passed through the feed forward network. The decoder also consists of both self attention and feed forward network layer. An additional layer is present in between these components which is an attention layer that helps the decoder to focus on the relevant parts of the input sentence.
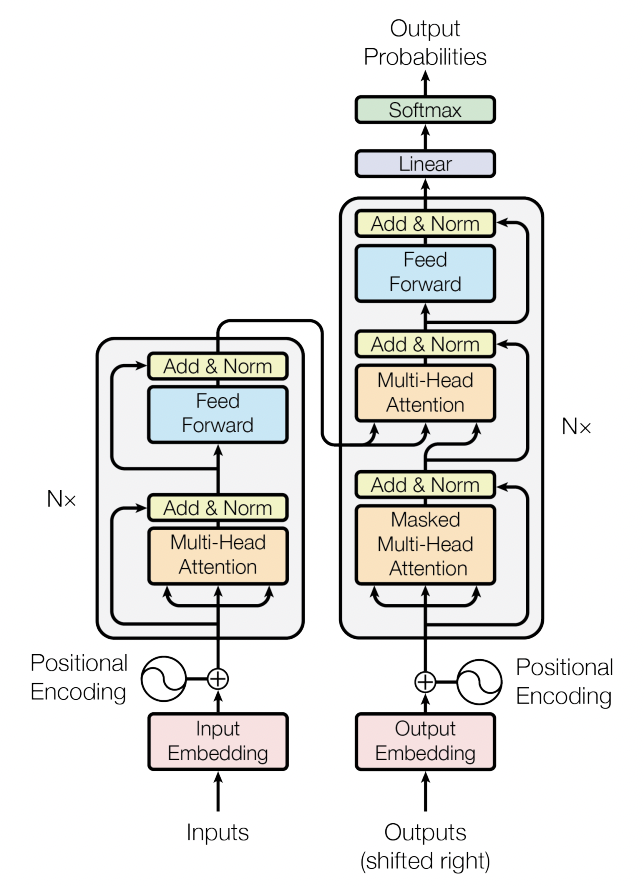
Huggingface Transformers provide various pre-trained models to perform NLP tasks. It provides APIs and tools to download and train state-of-the-art pre-trained models. Not only NLP, huggingface supports Computer Vision tasks like image classification, object detection and segmentation, audio classification and recognition, and multimodal tasks like table question answering, optical character recognition, and many more.
Basic transformer pipeline for summarization
Huggingface transformers provide an easy to use model for inference using pipeline. These pipelines are the objects that hide complex code and provide a simple API to perform various tasks.
from transformers import pipeline
classifier = pipeline("summarization")
text = """Acnesol Gel is an antibiotic that fights bacteria. It is used to treat acne, which appears as spots or pimples on your face, chest or back. This medicine works by attacking the bacteria that cause these pimples.Acnesol Gel is only meant for external use and should be used as advised by your doctor. You should normally wash and dry the affected area before applying a thin layer of the medicine. It should not be applied to broken or damaged skin. Avoid any contact with your eyes, nose, or mouth. Rinse it off with water if you accidentally get it in these areas. It may take several weeks for your symptoms to improve, but you should keep using this medicine regularly. Do not stop using it as soon as your acne starts to get better. Ask your doctor when you should stop treatment. Common side effects like minor itching, burning, or redness of the skin and oily skin may be seen in some people. These are usually temporary and resolve on their own. Consult your doctor if they bother you or do not go away.It is a safe medicine, but you should inform your doctor if you have any problems with your bowels (intestines). Also, inform the doctor if you have ever had bloody diarrhea caused by taking antibiotics or if you are using any other medicines to treat skin conditions. Consult your doctor about using this medicine if you are pregnant or breastfeeding."""
classifier(text)Result:
[{'summary_text': ' Acnesol Gel is an antibiotic that fights bacteria that causes pimples . It is used to treat acne, which appears as spots or pimples on your face, chest or back . The medicine is only meant for external use and should be used as advised by your doctor .'}]The pipeline() takes the name of the task to be performed (if we want to perform a question-answering task, then we can simply pass “question-answering” into the pipeline() and it automatically loads the model to perform the specific task.
Fine-tuning summarization model for medical dataset
Summarization using abstractive technique is hard as compared to extractive summarization as we need to generate new text as the output. Different architectures like GTP, T5, BART are used to perform summarization tasks. We will be using the PubMed dataset. It contains datasets of long and structured documents obtained from PubMed OpenAccess repositories. from datasets import load_dataset
pubmed = load_dataset("ccdv/pubmed-summarization")The PubMed dataset contains article, abstract and section_names as columns. The first step after loading the dataset is tokenizing the training data. Tokenization is the process of splitting paragraphs, sentences into smaller units called tokens. tokenizer = AutoTokenizer.from_pretrained(‘facebook/bart-large-cnn’)
The next step is to preprocess the data. Before training the data, we need to convert our data into expected model input format.
def preprocess_function(examples):
inputs = [doc for doc in examples["article"]]
model_inputs = tokenizer(inputs, max_length=1024, truncation=True)
labels = tokenizer(examples["abstract"], max_length=128, truncation=True, padding=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputsWe need to apply the processing function over the entire dataset. Setting flag batched=True helps to speed up the processing of multiple elements of the dataset at once.
tokenized_pubmed = pubmed.map(preprocess_function, batched=True)Next, we need to create a batch for all the examples. Huggingface provides a data collator to create a batch for the examples.
tokenized_datasets = tokenized_pubmed.remove_columns(pubmed["train"].column_names)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model="facebook/bart-large-cnn")Huggingface provides various pre-trained models that we can leverage to perform a variety of machine learning tasks.
model = AutoModelForSeq2SeqLM.from_pretrained(model)Before training the model, we need to define our training hyperparamaters using training arguments. Since text summarization is a sequence to sequence tasks, we are using Seq2SeqTrainingArguments. And, we need to define our trainer by passing training and test dataset along with training arguments.
# training arguments
training_arguments = Seq2SeqTrainingArguments(
output_dir='./results',
evaluation_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=3,
# remove_unused_columns=False,
# fp16=True,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_arguments,
train_dataset=tokenized_pubmed['train'],
eval_dataset=tokenized_pubmed['validation'],
tokenizer=tokenizer,
data_collator=data_collator
)The last step is to call train() to fine-tune our model.
trainer.train()