Deep Neural Networks tend to provide more accuracy as the number of layers increases. But, as we go more deeper in the network, the accuracy of the network decreases instead of increasing. As more layers are stacked, there occurs a problem of vanishing gradients. The paper mention that vanishing gradient has been addressed by normalized initialization and intermediate normalization layers. With the increase in depth, the accuracy gets saturated and then degrades rapidly.
*Vanishing gradient: Vanishing gradient is a situation where a deep multilayer feedforward network or RNN is unable to propagate useful gradient information from output end of the model to the layers near the input end of the model. In this case, the gradient becomes very small and prevents weights from changing its value. It causes network hard to train.
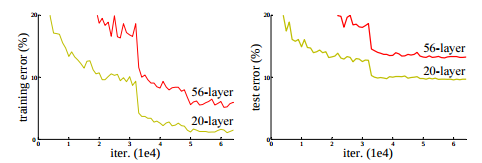
Training error (left) and test error (right) on CIFAR-10 with 20-layer and 56-layer “plain” networks source
The above figure shows that with the increase in depth of the network, training error increases thus increasing test error. Here, the training error on 20 layer network is less than that of 56 layer network. Thus, the network cannot generalize well for new data and becomes an inefficient model. This degradation indicates that increasing the model layer does not aid in the performance of the model and not all the system are easy to optimize.
The paper address the degradation problem by introducing a deep residual learning framework. The main innovation for ResNet is the residual module. Residual module is specifically an identity residual module, which is a block of two convolutional layers with same number of filters and a small filter size. The output of the second layer is added with the input to the first convolution layer.
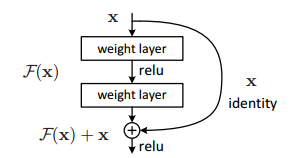
Residual learning: a building block. source
Network Architecture
The paper took baseline model of VGGNet as a plain network with mostly 3x3 filters with two design rules: a) for the same output feature map size, the layers have the same number of filters and b) if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer. The network is ended with a global average pooling layer and a 1000-way fully connected layer with a softmax.
Based on the plain network, shortcut connections are added to transform plain version into residual version.
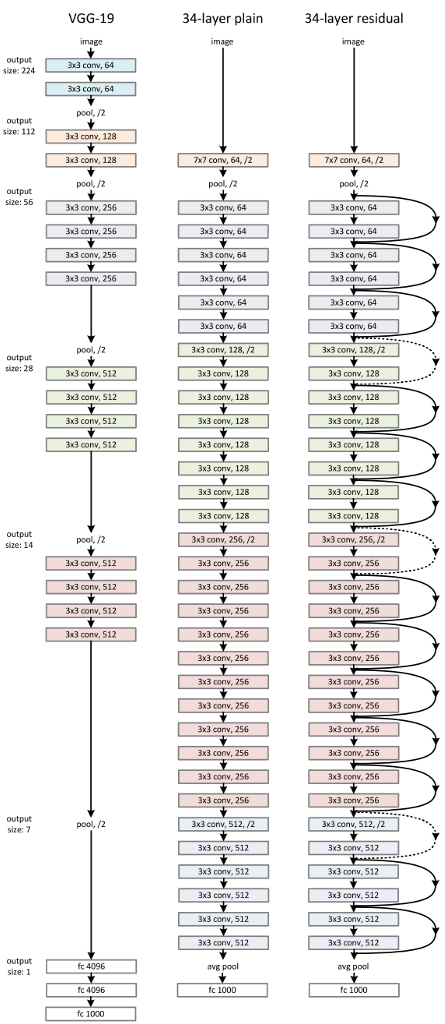
Left: VGG-19 model Middle: Plain network with 34 parameter layers Right: residual network with 34 parameter layers source
Implementation
- Image was first resized with its shorter side sampled into 256 x 480
- Data augmentation techniques was carried out
- Batch normalization was carried out after each convolution and before activation
- Stochastic gradient descent was used for training the network with mini batch of 256.
- Weight decay of 0.0001 and momentum of 0.9 was used.
Experiments
Resnet architecture was evaluated on ImageNet 2012 classification dataset consisting of 1000 classes. The model was trained on the 1.28 million training images and evaluated on the 50k validation images. Moreover, 100k images were used for testing the model accuracy.
While performing experiments on plain networks, a 34-layer plain network showed a higher validation error than an 18-layer plain network. Training error for the 34-layer plain network was found to be higher than the 18-layer plain network. Here, a degradation problem occurred as we go deep into the network. The deep plain networks may have a low convergence rate that impacts the accuracy of the model (impacts in reducing the training error).
Different from the plain network, a shortcut connection was added to each pair of 3x3 filters. With a same number of layers as in plain network, Resnet 34 performed better than Resnet 18 network. Resnet-34 showed less error and performs well in generalizing validation data. This resolves the problem of degradation as seen on a plain deep network. The comparison for both plain and residual network is shown below:
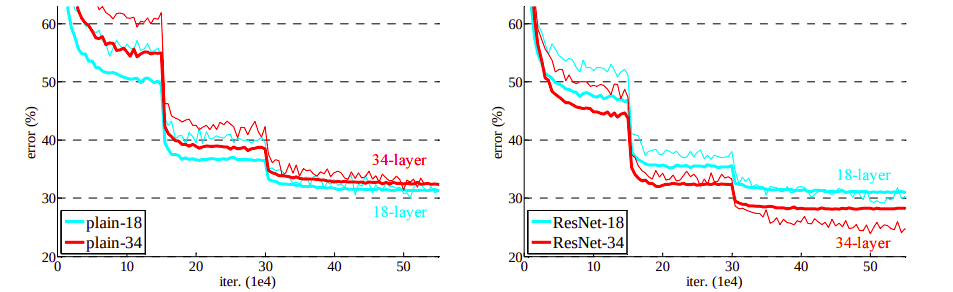
Training on ImageNet. Thin curves denote training error, and bold curves denote validation error of the center crops. Left: plain networks of 18 and 34 layers. Right: ResNets of 18 and 34 layers. In this plot, the residual networks have no extra parameter compared to their plain counterparts. source